本文将展示如何在 Habana® Gaudi®2 上使用 Optimum Habana。Optimum Habana 是 Gaudi2 和 Transformers 库之间的桥梁。本文设计并实现了一个大模型推理基准测试,证明了通过使用 Optimum Habana 你将能够在 Gaudi2 上获得 比目前市面上任何可用的 GPU 都快的推理速度。
Habana® Gaudi®2:https://habana.ai/training/gaudi2/
 (相关资料图)
(相关资料图)
Optimum Habana:https://hf.co/docs/optimum/habana/index
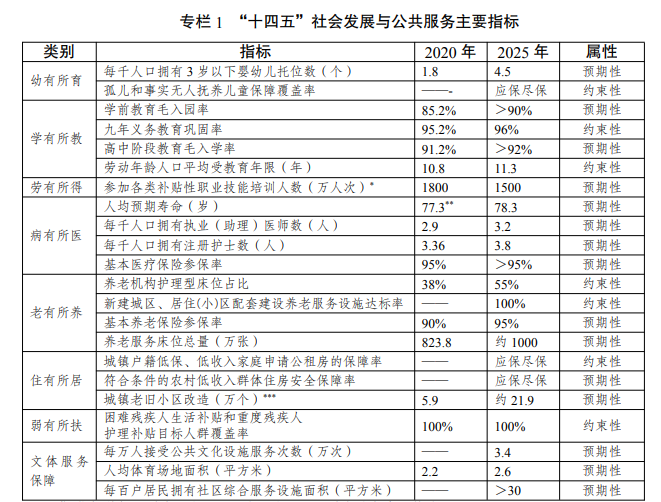
随着模型越来越大,将它们部署到生产环境中以用于推理也变得越来越具有挑战性。硬件和软件都需要很多创新来应对这些挑战,让我们来深入了解 Optimum Habana 是如何有效地克服这些挑战的!
BLOOM 是一个 1760 亿参数的自回归模型,经训练后可用于文本生成。它可以处理 46 种不同的语言以及 13 种编程语言。作为 BigScience 计划的一部分,BLOOM 作为一个开放科学项目,来自全球的大量的研究人员和工程师参与了模型的设计和训练。最近,我们又发布了架构与 BLOOM 完全相同的模型: BLOOMZ,它是 BLOOM 在多个任务上的微调版本,具有更好的泛化和零样本 [^1] 能力。
BLOOM:https://arxiv.org/abs/2211.05100
BigScience:https://bigscience.huggingface.co/
BLOOMZ:https://arxiv.org/abs/2211.01786
如此大的模型在 训练 和 推理 两个场景下都对内存和速度提出了新的挑战。即使是使用 16 位精度,一个模型也需要 352 GB 的内存!目前你可能很难找到一个具有如此大内存的设备,但像 Habana Gaudi2 这样先进的硬件已能让低延迟 BLOOM 和 BLOOMZ 模型推理变得可能。
训练场景:https://hf.co/blog/zh/bloom-megatron-deepspeed
推理场景:https://hf.co/blog/zh/bloom-inference-optimization
Gaudi2 是 Habana Labs 设计的第二代 AI 硬件加速器。单个服务器包含 8 张加速卡 (称为 Habana 处理单元 (Habana Processing Units),或 HPU),每张卡有 96GB 的内存,这为容纳超大模型提供了可能。但是,如果仅仅是内存大,而计算速度很慢,也没办法将其用于模型托管服务。幸运的是,Gaudi2 在这方面证明了自己,大放异彩: 它与 GPU 的不同之处在于,它的架构使加速器能够并行执行通用矩阵乘法 (General Matrix Multiplication,GeMM) 和其他操作,从而加快了深度学习工作流。这些特性使 Gaudi2 成为 LLM 训练和推理的理想方案。https://habana.ai/training/gaudi2/
Habana 的 SDK SynapseAI™ 支持 PyTorch 和 DeepSpeed 以加速 LLM 训练和推理。SynapseAI 图编译器 会优化整个计算图的执行过程 (如通过算子融合、数据布局管理、并行化、流水线、内存管理、图优化等手段)。
SynapseAI 图编译器介绍:https://docs.habana.ai/en/latest/Gaudi_Overview/SynapseAI_Software_Suite.html
此外,最近 SynapseAI 还引入了 HPU graphs 和 DeepSpeed-inference 的支持,这两者非常适合延迟敏感型的应用,下面的基准测试结果即很好地说明了这一点。
HPU graphs:https://docs.habana.ai/en/latest/PyTorch/Inference_on_PyTorch/Inference_Using_HPU_Graphs.html
DeepSpeed-inference:https://docs.habana.ai/en/latest/PyTorch/DeepSpeed/Inference_Using_DeepSpeed.html
以上所有功能都集成进了 Optimum Habana 库,因此在 Gaudi 上部署模型非常简单。你可以阅读 相应文档 快速起步。
Optimum Habana 库地址:https://github.com/huggingface/optimum-habana
快速入门链接:https://hf.co/docs/optimum/habana/quickstart
如果你想试试 Gaudi2,请登录 英特尔开发者云 (Intel Developer Cloud) 并按照 指南 申请。
英特尔开发者云 (Intel Developer Cloud):https://www.intel.com/content/www/us/en/secure/developer/devcloud/cloud-launchpad.html
申请指南:https://hf.co/blog/zh/habana-gaudi-2-benchmark
在本节中,我们将提供 BLOOMZ 在 Gaudi2、第一代 Gaudi 和 Nvidia A100 80GB 上的早期基准测试。虽然这些设备内存都不小,但由于模型太大,单个设备还是放不下整个 BLOOMZ 模型。为了解决这个问题,我们要使用 DeepSpeed,这是一个深度学习优化库,它实现了很多内存优化和速度优化以加速模型推理。特别地,我们在这里依赖 DeepSpeed-inference,它引入了几个特性,如 模型 (或管道) 并行 以充分利用可用设备。对 Gaudi2,我们使用 Habana 的 DeepSpeed 分支,其添加了对 HPU 的支持。
DeepSpeed:https://www.deepspeed.ai/
DeepSpeed-inference 论文链接:https://arxiv.org/abs/2207.00032
模型 (或管道) 并行介绍:https://hf.co/blog/zh/bloom-megatron-deepspeed
Habana 的 DeepSpeed 分支:https://github.com/HabanaAI/deepspeed
我们测量了两种不同大小的 BLOOMZ 模型的延迟 (batch size 为 1),两者参数量都有数十亿:
1760 亿 参数https://hf.co/bigscience/bloomz
70 亿 参数https://hf.co/bigscience/bloomz-7b1
我们使用 DeepSpeed-inference 以 16 位精度在 8 张卡上运行推理,同时我们开启了 key-value 缓存 优化。请注意,尽管 CUDA graphs 当前与 DeepSpeed 中的模型并行不兼容 (DeepSpeed v0.8.2,请参见 脚本第 158 行的内容,但 Habana 的 DeepSpeed 分支是支持 HPU graphs 的。所有基准测试都使用 贪心搜索 生成 100 个词元。输入提示为:
key-value 缓存:https://hf.co/docs/transformers/v4.27.1/en/model_doc/bloom
CUDA graphs:https://developer.nvidia.com/blog/cuda-graphs/
参考脚本:https://github.com/microsoft/DeepSpeed/blob/v0.8.2/deepspeed/inference/engine.py
贪心搜索:https://hf.co/blog/zh/how-to-generate
DeepSpeed is a machine learning framework” 该提示会被 BLOOM 分词器分成 7 个词元。
推理延迟测试结果如下表所示 (单位为 秒)。
模型卡数Gaudi2 延迟 (秒)A100-80GB 延迟 (秒)第一代 Gaudi 延迟 (秒)BLOOMZ83.7174.402/BLOOMZ-7B80.7372.4173.029BLOOMZ-7B11.0662.1192.865
Habana 团队最近在 SynapseAI 1.8 中引入了对 DeepSpeed-inference 的支持,从而快速支持了 1000 多亿参数模型的推理。对于 1760 亿参数的模型,Gaudi2 比 A100 80GB 快 1.2 倍。较小模型上的结果更有意思: 对于 BLOOMZ-7B,Gaudi2 比 A100 快 3 倍。有趣的是,BLOOMZ-7B 这种尺寸的模型也能受益于模型并行。
我们还在第一代 Gaudi 上运行了这些模型。虽然它比 Gaudi2 慢,但从价格角度看很有意思,因为 AWS 上的 DL1 实例每小时大约 13 美元。BLOOMZ-7B 在第一代 Gaudi 上的延迟为 2.865 秒。因此, 对 70 亿参数的模型而言,第一代 Gaudi 比 A100 的性价比更高,每小时能省 30 多美元!
我们预计 Habana 团队将在即将发布的新 SynapseAI 版本中继续优化这些模型的性能。在我们上一个基准测试中,我们看到 Gaudi2 的 Stable Diffusion 推理速度比 A100 快 2.2 倍,这个优势在随后 Habana 提供的最新优化中进一步提高到了 2.37 倍。在 SynapseAI 1.9 的预览版中,我们看到 BLOOMZ-176B 的推理延迟进一步降低到了 3.5 秒。当新版本的 SynapseAI 发布并集成到 Optimum Habana 中时,我们会更新最新的性能数字。https://hf.co/blog/zh/habana-gaudi-2-benchmark
我们的脚本允许支持模型整个数据集上逐句进行文本补全。如果你想在自己的数据集上尝试用 Gaudi2 进行 BLOOMZ 推理,这个脚本就很好用。
这里我们以 tldr_news 数据集为例。该数据每一条都包含文章的标题和内容 (你可以在 Hugging Face Hub 上可视化一下数据)。这里,我们仅保留 content 列 (即内容) 并对每个样本只截前 16 个词元,然后让模型来生成后 50 个词元。前 5 条数据如下所示:https://hf.co/datasets/JulesBelveze/tldr_news/viewer/all/test
下一节,我们将展示如何用该脚本来执行基准测试,我们还将展示如何将其应用于 Hugging Face Hub 中任何你喜欢的数据集!
示例脚本 提供了用于在 Gaudi2 和第一代 Gaudi 上对 BLOOMZ 进行基准测试的脚本。在运行它之前,请确保按照 Habana 给出的指南 安装了最新版本的 SynapseAI 和 Gaudi 驱动程序。
示例脚本:https://github.com/huggingface/optimum-habana/tree/main/examples/text-generation
Habana 给出的指南:https://docs.habana.ai/en/latest/Installation_Guide/index.html
然后,运行以下命令:
最后,你可以按如下方式运行脚本:
对于多节点推理,你可以遵循 Optimum Habana 文档中的 参考指南。https://hf.co/docs/optimum/habana/usage_guides/multi_node_training
你还可以从 Hugging Face Hub 加载任何数据集作为文本生成任务的提示,只需使用参数 --dataset_name my_dataset_name。
此基准测试基于 Transformers v4.27.1、SynapseAI v1.8.0,而 Optimum Habana 是从源码安装的。
对于 GPU,此代码库 里包含了 可用于复现这篇文章结果的脚本。要使用 CUDA graphs,需要使用静态数据尺寸,而 Transformers 中不支持这一用法。你可以使用 Habana 团队的 参考代码 来使能 CUDA graphs 或 HPU graphs。
代码库地址:https://github.com/huggingface/transformers-bloom-inference/tree/main/bloom-inference-scripts
脚本地址:https://hf.co/blog/zh/bloom-inference-pytorch-scripts
参考代码:https://github.com/HabanaAI/Model-References/tree/1.8.0/PyTorch/nlp/bloom
通过本文,我们看到, Habana Gaudi2 执行 BLOOMZ 推理的速度比 Nvidia A100 80GB 更快。并且无需编写复杂的脚本,因为 Optimum Habana 提供了易于使用的工具用于在 HPU 上运行数十亿参数模型的推理。Habana 的 SynapseAI SDK 的后续版本有望提高性能,因此随着 SynapseAI 上 LLM 推理优化的不断推进,我们将定期更新此基准。我们也期待 FP8 推理在 Gaudi2 上带来的性能优势。https://hf.co/docs/optimum/habana/index
我们还介绍了在第一代 Gaudi 上的结果。对于更小的模型,它的性能与 A100 比肩,甚至更好,而价格仅为 A100 的近三分之一。对于像 BLOOMZ 这样的大模型,它是替代 GPU 推理的一个不错的选择。
如果你有兴趣使用最新的 AI 硬件加速器和软件库来加速你的机器学习训练和推理工作流,请查看我们的 专家加速计划。要了解有关 Habana 解决方案的更多信息,可以 从后面的链接了解我们双方的相关合作并联系他们。要详细了解 Hugging Face 为使 AI 硬件加速器易于使用所做的工作,请查看我们的 硬件合作伙伴计划。
专家加速计划:https://hf.co/support
关于双方相关合作的介绍和联系方式:https://hf.co/hardware/habana
硬件合作伙伴计划:https://hf.co/hardware
更快训推: Habana Gaudi-2 与 Nvidia A100 80GBhttps://hf.co/blog/zh/habana-gaudi-2-benchmark
在 Hugging Face 和 Habana Labs Gaudi 上用 DeepSpeed 训练更快、更便宜的大规模 Transformer 模型https://developer.habana.ai/events/leverage-deepspeed-to-train-faster-and-cheaper-large-scale-transformer-models-with-hugging-face-and-habana-labs-gaudi/
感谢阅读!如果你有任何问题,请随时通过 Github 或 论坛 与我联系。你也可以在 LinkedIn 上找到我。
Github:https://github.com/huggingface/optimum-habana
Hugging Face 论坛:https://discuss.huggingface.co/c/optimum/59
LinkedIn:https://www.linkedin.com/in/regispierrard/
[^1]: “零样本”是指模型在新的或未见过的输入数据上完成任务的能力,即训练数据中完全不含此类数据。我们输给模型提示和以自然语言描述的指令 (即我们希望模型做什么)。零样本分类不提供任何与正在完成的任务相关的任何示例。这区别于单样本或少样本分类,因为这些任务还是需要提供有关当前任务的一个或几个示例的。
英文原文: https://hf.co/blog/habana-gaudi-2-bloom
作者: Régis Pierrard
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
审校、排版: zhongdongy (阿东)
标签:


 全球时讯:赶尽杀绝 1080p_赶尽杀绝未删减版
全球时讯:赶尽杀绝 1080p_赶尽杀绝未删减版
 山西一季度煤炭产量达3.35亿吨 创单季度新高|天天播资讯
山西一季度煤炭产量达3.35亿吨 创单季度新高|天天播资讯
 公告速递:华夏野村日经225ETF基金暂停申购、赎回业务-世界热文
公告速递:华夏野村日经225ETF基金暂停申购、赎回业务-世界热文
 青海西宁2022下半年教资阳性考生申报入口+咨询电话-短讯
青海西宁2022下半年教资阳性考生申报入口+咨询电话-短讯
 呼和浩特美团外卖消费券怎么用?附使用规则
呼和浩特美团外卖消费券怎么用?附使用规则